JsonLLM: Getting LLMs to follow some rules
Overview
This is a bit of a long post, in it I go over:
- My struggles with making Large Language Model (LLM) agents using open source models
- Various ways to force LLMs to output in a specific format
- Open source projects for guiding LLMs with logit processing
- My contribution: JsonSchema to Context Free Grammar compiler
- Funny little bugs and learnings made along the way
The Motivation
I have become particularly interested in running private on-prem LLM agents, like a real sci-fi AI personal assistant. I want something that can do things like read my emails, edit my calendar, interact with my smart home, and maybe in the future plan whole events and buy things on my behalf. I wanted it to be all on prem, self hosted, so that all my data stays on-site. I think if AI is going to be running a large part of my life I’d like to know how it all works, and be running the majority of it myself.
The Problem
The Open source LLMs I’ve tried have approximate knowledge of many things, and are reasonably smart when pushed in the right directions. I found they can get the jist of what I wanted, but when you actually get down to trying to produce structured parsable text to build function arguments from, it was particularly flakey.
For example, I want it to be able to read an email, and put events in my calendar. A naive way to do this would be to write a python script that scans for new emails, and on each email prompt the AI with something like (note this is using completion, not chat):
prompt = """\
Content of an email:
{email_content}
List of calendar events in JSON format like \{"title": "title_string", "date": "dd-mm-yyyy"\}:
""".format(email_content=email_content)
And then have some smart python code to parse the JSON, validate the values, and pass them to a python function that calls the Gmail API. This is prone to many formatting, parsing, and validation issues, like it might get the date wrong, hallucinate extra fields, or not even return the desired json at all.
GPT-4 could probably do it easily, but the open source models I can run (like Vicuna 13B) would have a hard time doing it reliably. Also as you start doing more complicated stuff, even GPT-4 struggles.
The fundamental idea here is that you are relying on the LLM to understand the format you want the data in (JSON), as well as the idea you want it to produce (new calendar events). The former is very strict, grammatical, and can be defined programmatically, and the latter is purely semantic in the realm of natural language understanding, which is the magic that these LLMs are useful for.
The Solution
There are many ways to tackle the parsing problem, here are some potential solutions:
- Use a better LLM that can understand the format (i.e. use GPT-4)
- Use clever prompt engineering and build your structured output from some smart chained LLM calls
- Guide the LLM at generation time to ensure that it always produces valid text (with logit processing)
Seeing as I wanted to do everything on premise, and don’t want to buy an 8xA100 rig for my little home server, using bigger models was not a viable option.
The prompt engineering route is likely to have varying reliability between models, as some prompt engineering tricks may differ in efficacy between LLMs. It also may be extremely inefficient, and you’re still relying on the model to understand the format.
The third option is a bit more complicated but would guarantee the generation would be valid according to some specification. And depending on how it was implemented could be very versatile. This would mean I could have an LLM produce JSON objects that follow a provided JsonSchema.
I ended up going with the third option, logit processing.
Logit Processing
When a GPT-like language model is generating text, it starts with a user provided prompt, tokenizes the text, embeds the tokens as vectors, and runs that sequence of embedded tokens through a complicated neural network (not going into detail here as it is not relevant). The result from the network is a logit per token in the model’s vocabulary, and using a softmax operation each token’s logit is converted to the probability that that specific token will come next in the sequence (according to the model). Here is a brief overview:

In the above example the token with the highest probability is chosen, this isn’t always the case, and there are many potential ways to sample the next token (see beam search, top k, top p methods).
In essence, the LLM guidance method I want to use will tap into the text generation process at step three and lower the probabilities of (a.k.a. mask) invalid tokens. This means the generated text will always follow a certain pattern, the hard part now being how do we choose what tokens to mask?
Regular Expressions
When describing patterns in text, regular expressions are king. Leveraging these expressions to guide LLM text generation would be a great start, and to back that up, a bunch of really smart people have already built tools to do it 😍. ReLLM is a good example of such works, and is the one I chose to base my work on.
The way this works is buy leveraging “partial matches”. This isn’t in the python built-in re package but a feature of the regex library, and is basically a match on a string that could still end up matching the pattern.
For example consider the pattern [abc]+[0-9] which matches any sequence of the a,b,c characters (with at least 1 character) followed by a single digit.
Some standard full matches (meaning they match the whole string) are:
aaaaa1bca2bbbbbbbb4
Some partial matches are (any combination of abc characters):
bbbbbbabc
Some examples of strings that won’t fully match (they may contain matches, but the whole string isn’t a match):
1abcabc5abcsabc3
So what we can do is ensure that the language model’s whole generation is at least a partial match of the provided pattern. At each token selection step, for each potential token, we can concatenate the token text to the end of the current completion and check if the result is at least a partial match for the provided pattern. If the result doesn’t match we can set the probability of that token to 0 (by setting the logit to a massively negative number), and then continue with the standard token sampling. This will result in the generation only being able to select tokens that adhere to the pattern.
Context Free Grammars
While regular expressions are valuable for describing patterns, they do fall short in certain areas. For instance, they lack the capacity to describe content that follows a specific syntax with nested patterns, which is definitely required for things like JSON data or python function arguments.
But also found in the well established computer science problem-solving toolbox, there is something designed specifically to operate beyond the limitations of regular expressions - and that tool is the Context-Free Grammar (CFG).
Fundamentally, a Context-Free Grammar is a set of rules that describe all possible strings in a given formal language. It acts as a tool that provides guidance on language syntax, useful for programming languages, and provides the basis for parsing in many compiler designs.
For example, this is a rough CFG that describes valid JSON objects:
JSON := OBJECT | ARRAY
OBJECT := '{' PAIRLIST? '}'
PAIRLIST := PAIR (',' PAIR)*
PAIR := STRING ':' VALUE
VALUE := STRING | NUMBER | OBJECT | ARRAY | 'true' | 'false' | 'null'
ARRAY := '[' VALUELIST? ']'
VALUELIST := VALUE(',' VALUE)*
STRING := '"' [a-z, A-Z, 0-9]* '"'
NUMBER := [0-9]+
By using this CFG to mask invalid tokens at each step of the LLM generation process, much like how we did with the regular expressions, we could ensure that the final output is a valid JSON object. Implementing it, however, is a bit more complicated - but as with regular expressions there is some prior art out there in the open source community! See ParserLLM, this is the one I’ve based my work on, it’s made by the same person as ReLLM, Matt Rickard.
This works by breaking the CFG into it’s potential next “terminals”, these terminals are explicit patterns in the text and can generally be represented by regular expressions. And because they can be represented by regular expressions, we can just figure out what terminals can come next, and chuck it into ReLLM! Too easy.
Awesome, so now we can guide LLM generation (mostly) with Context Free Grammars the only hard part is making the CFG. This is a pretty involved task and seeing as most of my use-cases are satisfied with JSON objects there is room for some automation here.
Json Schema
This is where I actually make some novel contributions to the problem at hand. CFGs are very powerful and very cool, but they are not commonly known or used by the average software developer - I really wanted to make this guided LLM completion easy to use.
I am a big fan of the pydantic python library and was keen to find a way to use pydantic models to guide LLM generation. Most python classes inheriting from pydantic.BaseModel have a .schema() method that can be used to generate a JsonSchema for the model. These JsonSchema’s are a schematic that completely describes what a valid JSON object looks like for that model.
This is a good starting point, if I am able to automatically convert a JsonSchema to a CFG that matches valid JSON objects of that schema, I could leverage pydantic to make an extremely accessible way of guiding LLM generation. This isolates the complexity to a translation between two schemas: JsonSchema to CFGs.
So I have written a very simple JsonSchema to CFG compiler here that supports the basic attributes of JsonSchema (objects, lists, strings, numbers, booleans), and is easy to extend as needed. I don’t think you can represent all the JsonSchema features in CFGs (i.e. numeric constraints, list lengths), but so far I’ve been able to add enough to do some decent damage.
This is awesome, because it allows me to write some very clean python code to guide LLM generation. For example, all combined together, code like this is possible (still needs to be implemented this cleanly):
# Load in a language model
model = load_llm()
# Define the desired shape of your LLM output, i.e. the attributes you'd like
class CalendarEvent(BaseModel):
start_time: datetime
end_time: datetime
title: str
# Pass the model schema, and the prompt into our LLM generation frameworkRegexCompletionRequest
event = generate_json_from_schema(
prompt="define a calendar event in json starting at... etc",
schema=CalendarEvent.schema(),
model=model,
)
# Call your python function to add the event to your calendar
add_calendar_event(event, calendar_service)
I’m still working on the code - but that’s the dream.
Current Status
I’m still working away at this, there are a bunch of finicky issues I’ve run into with this approach which I’ll outline a bit later in the post, but currently I have:
- All code in this repo
- A working JsonSchema to CFG compiler
- My own copy of ReLLM and ParserLLM with significant correctness and performance improvements (still waiting for my PRs to be merged upstream)
- A very basic inference server using FastAPI and leveraging HuggingFace’s transformers library
- A pythonic client for the inference server
- A LangChain client for the inference server so I can leverage the LangChain agent tooling
My future plans are to make these into easy to use open source libraries/tools, and to add other schema languages. However the most important problem right now is getting the language model generation perfect, figuring out what LLMs work well, and what prompt’s work best for the guided token generation we’re doing.
Funny bugs, Learnings, and Experiments
Here are some interesting things I’ve learnt, features added, and funny bugs I’ve ran into. This project is still a WIP, so some of these I’m still working on.
Infinite Generation
Most of the persistent bugs I encountered were around when the model is trying to end a potentially infinite pattern. For example a floating point number with potentially infinite decimal places.
I ended up with some funny responses like: {"name": "Steve", "age": 25.0000000200160435}, where the LLM only finished the age field because I had specified a maximum number of decimal places in the CFG terminal regular expression. Here are two solutions I’ve explored to solve this:
Summed Token Probabilities
One solution I came up with to help the text generation with these potentially infinite patters was to look at the summed probability of all valid tokens, if that probability was really small, stop generating. Here is an example where it’s trying to generate an email address:
Prompt: My name is Jerome Swannack, I work at coolcompany.com and my email address is
Pattern: [a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+[a-zA-Z0-9]
Output: ian.swannack@gmail.com.au.I.I.I.I.I.I.I.I.I.
First off, Ian? 🤦 Oh well. Secondly the pattern allows infinite subdomains in the email address, and the model takes it’s liberty and adds a bunch of .Is. I figure this is surely not what the model wants to be doing, and we should be terminating the sequence after .com. To demonstrate this I have calculated the probability of all tokens at each step of the model generation, then summed all the probabilities of tokens allowed by our guided generation. This effectively shows the probability that the model would have selected one of our guided tokens off its own accord.
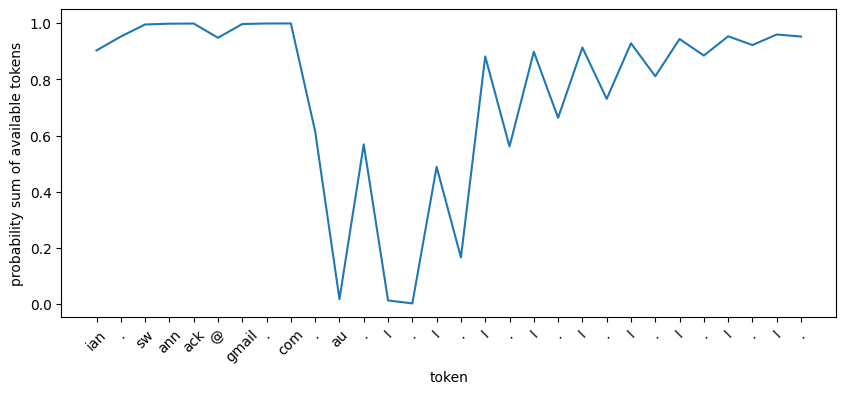
As you can see the guidance has little effect on the generation prior to .au, after which the probability drops off a cliff (and then comically raises after a few .Is). This is where our guided generation is forcing the LLM to do weird things, and we should use that low probability as a sign that we should stop generating. I added a prob_limit field to my copy of rellm to enable this type of sequence termination. On a side note, there is a little dip in probability at the start near ian… I wonder if that’s also the guidance’s fault 😬.
For a neat interactive view of the token selection, check this out
Smarter Token Selection
Another approach (that I am currently tinkering with) is to adjust the token selection logic, currently only tokens that result in a partial completion that is all included in a partial match (in the regex library this is pattern.fullmatch(..., partial=True)). However we can be smarter here and add an additional condition: A normal non-partial match on a substring of the completion, where the match starts at the beginning and has a length longer than the original completion (without the new token added).
This would mean when trying to generate text on a number like: 27.0 with a pattern matching all valid floating point numbers, it would allow the model to accept a token like 0, , where the result is 27.00, , a technically invalid string. The model has added meaning content (the last 0) and indicated it wants to terminate the string (with , ). So we can just accept that token, and upon exiting the completion function, only return the matching string 27.00.
Early Stopping
The opposite issue to the infinite generation is that of early stopping. In the original ReLLM package, the generation would either stop as soon as a match was found or when the max tokens was reached. The max tokens end condition is generally unsatisfactory, and the stop on match criteria is slightly too aggressive.
For example, if you’re matching an integer number with [0-9]+, the generation would return on the very first digit (or token with digits in it). This is not ideal as the desired value may have been significantly longer.
In conjunction with the smarter token selection above (allowing for invalid token selection), we can generate until a full match is found, then keep going until there is no longer a full match or full partial match, i.e. the match is shorter than the completion, and there is no way to end up with another match by adding additional tokens.
Empty tokens
I noticed while debugging the guided generation that the model was repeatedly selecting many empty tokens. I haven’t investigated what all the empty tokens were, but I found that some of them corresponded to special tokens like <endoftext>, and the transformers library was masking them to avoid weird LLM outputs by making them come up as empty tokens.
In any case, I think the model selecting an empty token is a way of opting to end generation. So I made rellm only allow empty tokens if a match is already found, and if an empty token is selected we end generation.
Skip LLM Generation of Constant Regex Patterns
An inefficiency that bugged me in the existing parserllm and rellm implementations is that if there was a regex that only matched a single string, there was no point in getting the language model to generate that text. I added a little function to check if a regex pattern was constant, and if it is, just return the constant value.
This sped up things like JSON generation from JsonSchema immensely, as a lot of the generated text is curly braces and JSON keys. i.e. things like {"name": would be generated without calling the LLM.
Special Symbols
The latest bug I’ve bumped into is special symbols in LLM tokenizers. For example in GPT-2’s tokenizer characters like Ġ can symbolise spaces and newlines. This naturally throws off the token masking and results in selecting very low probability tokens. I believe adding a special symbol map per tokenizer will be needed to avoid this.
Links
Prior Art
- Jsonformer
- Implements a state machine for JsonSchema, prunes tokens according to the state machine
- ReLLM
- Uses partial matching of regex to prune tokens so that the generated string matches the pattern.
- ParserLLM
- Uses CFGs and the Lark library to get the regex for use in ReLLM, resulting is generations that match the CFG
- OpenAI functions
- Unknown, looks like prompt engineering or similar, but there is logit bias in some of their other APIs
- LMQL
- Very interesting approach to programming with LLMs
- Automorphic’s Trex
- Looks very similar to this project, but doesn’t have JsonSchema.
- gpt-json
- An open source prompt engineering approach, has awesome pydantic integration
- llama.ccp